


Indice dei contenuti
Contributi alla Comunità di Siril
Introduzione
L’astrofotografia amatoriale è cambiata profondamente negli ultimi anni, e buona parte di questa evoluzione si deve alla crescita e al miglioramento degli strumenti software. In questo scenario, Siril ha conquistato un ruolo di primo piano: è un software open-source, potente e multipiattaforma, pensato appositamente per chi lavora con immagini astronomiche. Dalla calibrazione delle immagini con dark, bias e flat, alla registrazione (allineamento) e all’integrazione di centinaia di pose in un’unica immagine finale (stacking)1.

Siril offre agli astrofili tutto ciò che serve per trasformare i dati grezzi delle foto astronomiche in immagini pronte per l’analisi scientifica o la pubblicazione a scopi divulgativi o semplicemente da condividere con passione sui social.

Tuttavia, è importante ricordare che Siril offre molto più del semplice utilizzo di calibrazione e stacking delle immagini, il potenziale del software va ben oltre.
Ad esempio, consente di:
- analizzare le immagini in modo avanzato (Fig. 2), combinando criteri multipli per filtrare, ordinare o confrontare pose;
- eseguire fotometria differenziale e curve di luce, utili per lo studio di esopianeti, stelle variabili o eventi transitori;
- realizzare astrometria precisa, con riconoscimento automatico degli oggetti presenti nell’immagine;
- integrare librerie esterne Python per operazioni scientifiche complesse, come la riduzione dati o la modellazione.
Un riconoscimento importante, che conferma quanto Siril, pur essendo gratuito, sia ormai uno strumento maturo e affidabile anche per la ricerca scientifica professionale.
Per sfruttare appieno tutte queste potenzialità, è necessario andare oltre la semplice esecuzione di script e immergersi nella documentazione ufficiale, nei tutorial disponibili e nella community.
Con la versione 1.4.0, Siril ha introdotto una novità importante: l’integrazione di un ambiente Python interno VENV (virtual environment)2 completamente gestito dal programma. Non si tratta solo di una nuova funzione, ma di una vera svolta, che apre le porte a un modo completamente nuovo di personalizzare e automatizzare il lavoro.
Python è un linguaggio di programmazione di alto livello, versatile e facile da leggere, pensato per essere chiaro e accessibile anche a chi non è uno sviluppatore professionista. Proprio grazie alla sua semplicità, negli anni è diventato lo strumento preferito in moltissimi ambiti scientifici e accademici.
Il vero punto di forza di Python risiede nel suo vastissimo ecosistema di librerie specializzate: moduli già pronti per ogni esigenza, che permettono di affrontare calcoli complessi o analisi dati senza dover reinventare tutto da zero.
Solo per citarne alcune:
- NumPy e SciPy per il calcolo numerico ad alte prestazioni;
- Matplotlib e Plotly per la visualizzazione dei dati;
- OpenCV per l’elaborazione di immagini e computer vision;
- e naturalmente Astropy, una libreria pensata appositamente per l’astronomia.
Quest’ultima consente, ad esempio, di gestire file FITS3, convertire coordinate celesti e molto altro ancora.
E per l’utente comune? Nessun incubo da installazioni o righe di comando. Non serve configurare nulla a mano: è Siril che fa tutto da solo. Se uno script ha bisogno di librerie esterne come NumPy o OpenCV, le scarica e le installa automaticamente nel suo ambiente Python VENV separato da tutto il sistema, senza toccare, compromettere o entrare in conflitto con il resto del sistema.
Una “zona sicura” dove gli script possono lavorare in modo isolato, senza correre il rischio di entrare in conflitto con altre versioni di Python già installate sul computer.
E se qualcosa dovesse andare storto (sempre e solo dentro l’ambiente Python VENV di Siril)? Nessun problema: basta un semplice comando da Siril per resettare tutto l’ambiente e ripartire da zero. Una funzione comoda che risolve in un attimo eventuali instabilità.
È un approccio davvero intelligente: semplice per l’utente, stabile per il sistema e sicuro per i dati.
Grazie a questa architettura, oggi anche chi non ha mai scritto una riga di codice può usare — o persino creare — strumenti su misura (è integrato in Siril un editor per script Python), automatizzare operazioni ripetitive o sperimentare con idee nuove. Un passo avanti enorme rispetto al passato, che ha reso possibile (almeno per quanto mi riguarda) lo sviluppo del set di strumenti presentati in questo articolo.
Il set comprende cinque tool, ognuno pensato per risolvere un problema specifico o per rendere più semplice una fase del flusso di lavoro. Si va dalla gestione dei file con “Sequence Deleter“, all’analisi diagnostica dei flat “Flat on Flat Analyzer“, passando per strumenti di elaborazione creativa come “Hubble Palette from OSC” e “Signature Tool“, fino ad arrivare al recupero di dati, grazie a “Satellite Trail Remover“, uno script avanzato per la rimozione semi automatica delle tracce di aerei o satelliti artificiali.
Sequences Deleter
l’ARTICOLO COMPLETO è riservato agli abbonati alla versione digitale. Per sottoscrivere l’abbonamento Clicca qui. Se sei già abbonato accedi al tuo account dall’Area Riservata
[swpm_protected for=”3″]
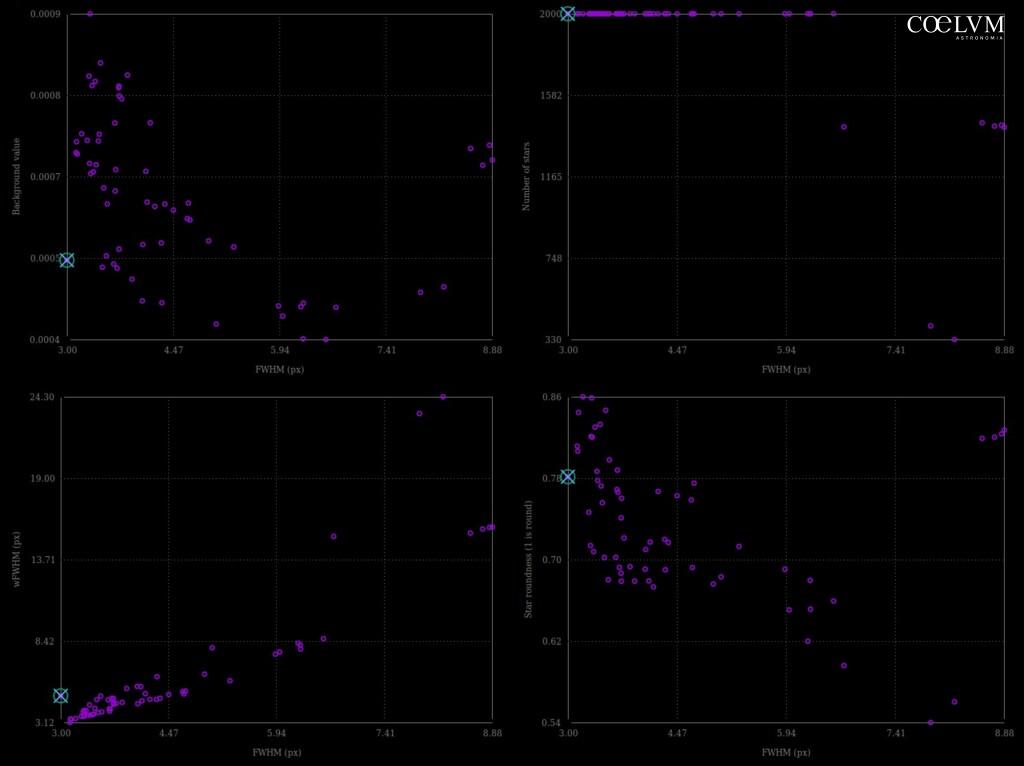
Un’utilità essenziale per la gestione del workflow, progettata per essere molto più di un semplice “cancellatore” di file. Durante una sessione di elaborazione (che sia deep sky, planetario o paesaggistica notturna), è comune creare numerose sequenze intermedie, di prova o anche errate. E quando si ha a che fare con file FITS provenienti da una camera astronomica con sensore APS-C (formato/dimensioni classiche di un sensore CMOS) i file FITS possono occupare dai 50MB ai 300MB ognuno.
Con un rapido calcolo, una sequenza di 50 immagini FITS da 300 MB ciascuna occupa già circa 15 GB. Tuttavia, durante l’elaborazione, a ogni passaggio verranno create copie di tutti e 50 i file: lo spazio occupato salirà così a 30 GB, poi a 45 GB, e così via.
Potrebbe sembrare un enorme spreco di spazio, ma è l’unico modo per conservare una “storia” delle operazioni effettuate e poter tornare indietro senza dover ricominciare da zero.
Del resto, ogni passaggio richiede notevoli risorse di sistema e, su macchine poco potenti, i tempi di attesa possono facilmente arrivare a 15 o 30 minuti.
Questo script nasce con l’obiettivo di semplificare il lavoro di “pulizia” dei file copia generati durante le fasi di elaborazione.
A questo punto, la domanda sorge spontanea (e vi assicuro che è stata posta più volte al team di Siril):
perché Siril non include una funzione per cancellare automaticamente questi file copia?
La risposta breve è semplice: Siril non è pensato per ripulire l’hard disk.
Nel modello concettuale del software, lo spazio di lavoro è una directory isolata che può essere eliminata completamente una volta conclusa l’elaborazione.
I programmatori, comprensibilmente, concentrano i loro sforzi sul miglioramento degli algoritmi di elaborazione — che sono già molto complessi — piuttosto che su funzioni accessorie di gestione dei file.
Una scelta del tutto comprensibile, soprattutto considerando che Siril è un software gratuito, a differenza di molti altri strumenti simili che richiedono costosi abbonamenti o licenze.
Tuttavia, proprio da qui — e da numerose osservazioni raccolte durante i corsi di astrofotografia che teniamo in ATA — è nata l’idea di questo script.
Non tutti, infatti, dispongono di computer con prestazioni elevate o grandi capacità di archiviazione.
L’obiettivo è quindi fornire un piccolo strumento, sfruttando le nuove funzionalità offerte da Python in Siril, che permetta una pulizia mirata, senza dover eliminare l’intera directory, rimuovendo solo quei file copia che non servono più.
Lo script si rivolge anche agli utenti meno esperti nella gestione dei file, che spesso si trovano in difficoltà nel capire cosa sia sicuro eliminare e cosa no. La paura di cancellare per errore i file originali è molto diffusa — e più che giustificata.
Sequences Deleter, non cancella i file basandosi su maschere 4 di nomi generiche, ma adotta un approccio molto più robusto e sicuro. Lo script è stato progettato ispirandosi alla gestione interna delle sequenze di Siril (definita nel file sorgente “seqfile.c”), ed esegue quindi un’analisi dettagliata del file .seq associato alla sequenza selezionata.
Attraverso il parsing 5 di questo file, lo script è in grado di determinare la natura esatta della sequenza: se si tratta di una sequenza regolare (con nomi file progressivi, es. light_0001.fit, light_0002.fit), di una sequenza variabile composta da file FITS specifici, o di una sequenza basata su container come file SER o AVI.
Una volta estratte le informazioni precise sui file che compongono la sequenza, procede alla loro eliminazione mirata.
Questo metodo garantisce che vengano rimossi solo ed esclusivamente i file pertinenti, inclusi i file di conversione, prevenendo cancellazioni accidentali e mantenendo l’integrità della directory di lavoro.
A completamento del processo, lo script stampa nella scheda “Console” di Siril l’elenco dettagliato dei file eliminati, offrendo così all’utente una verifica immediata delle operazioni effettuate.
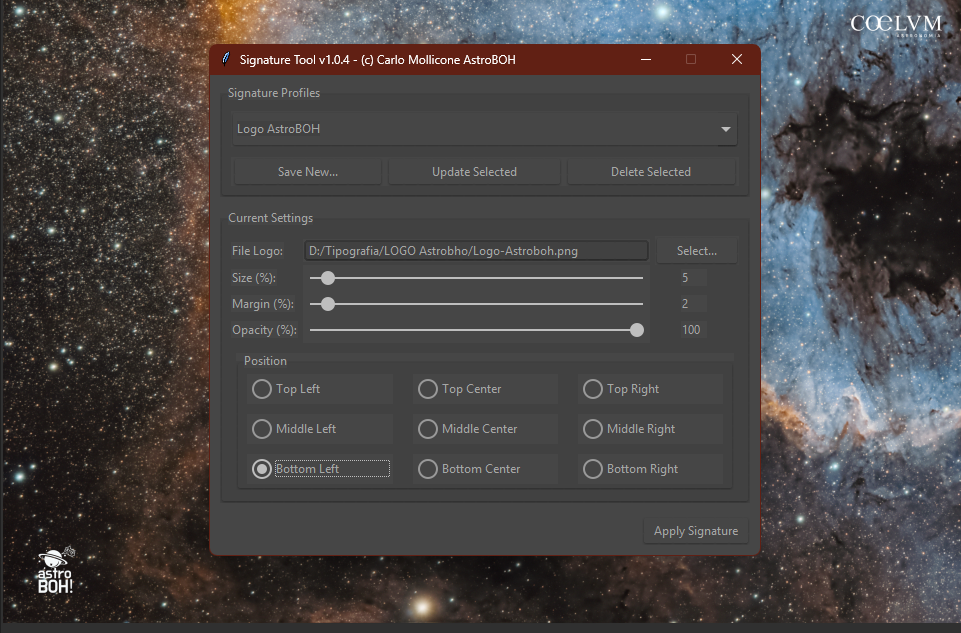
Signature Tool
Applicare una firma o un logo a una foto può sembrare un dettaglio, ma in realtà ha diversi scopi importanti, soprattutto se si condividono le immagini online o si lavora in ambito creativo.
Prima di tutto, serve a tutelare l’autore. Una firma o un piccolo logo in un angolo della foto dice chiaramente: questa immagine è mia, è frutto del mio lavoro, del mio tempo e della mia visione. In rete, dove le immagini viaggiano velocemente e possono essere scaricate, riutilizzate o persino spacciate per proprie da altri, avere una firma è un modo semplice per mantenere almeno un minimo di riconoscibilità.
Poi c’è l’aspetto della visibilità. Per chi pubblica foto per passione o per lavoro, avere un marchio riconoscibile aiuta a farsi notare. Se un’immagine gira su forum, social o siti, chi la guarda può risalire all’autore, visitare il suo profilo o sito, magari scoprire altri lavori.
Infine, è anche una forma di stile personale. Alcuni fotografi disegnano firme minimali, altri usano loghi eleganti: è un dettaglio, ma contribuisce a dare un’identità visiva alle proprie immagini.
Ora, applicare una firma a un’astrofotografia potrebbe sembrare un’operazione semplice (dopo tutti i complicati processi che sono stati necessari per elaborarla): prendere un file PNG, gestire il suo canale di trasparenza e fonderlo con l’immagine ed il gioco è fatto. La realtà, tuttavia, nasconde complicazioni significative.
Il flusso di lavoro in Siril — come in molti altri software di elaborazione astronomica — deve gestire immagini con profondità di colore differenti: 8, 16 e persino 32 bit per canale.
Se l’8 bit è lo standard comune nella fotografia tradizionale e nell’uso generico dei software di grafica, le immagini astronomiche richiedono una profondità molto maggiore per preservare le deboli sfumature di luce, le strutture diffuse e i dettagli nascosti nei bassi livelli di segnale.
Le immagini a 16 bit offrono già 65.536 livelli di intensità per canale, contro i soli 256 dell’8 bit. Ma con l’uso di stack, elaborazioni lineari e operazioni matematiche complesse, è facile superare anche questa soglia, arrivando a lavorare a 32 bit.
Tuttavia, la maggior parte dei software di fotoritocco non è in grado di gestire correttamente i file a 16 o 32 bit in virgola mobile.
Quando riescono ad aprirli, spesso li convertono silenziosamente a 8 bit o a un’intera gamma compressa, perdendo enormi quantità di informazioni — specialmente nei livelli più bassi, dove si annidano dettagli fondamentali dell’immagine astronomica.
Questa perdita non è banale: significa compromettere la dinamica originale, degradare i gradienti, introdurre banding, o peggio ancora, falsare i dati in modo irreversibile.
Per questo motivo, anche un’operazione apparentemente banale come l’aggiunta di una firma, se eseguita su file a 16 o 32 bit, deve necessariamente preservare l’integrità del dato, evitando qualsiasi ricampionamento, conversione di profondità o manipolazione che possa compromettere il contenuto scientifico dell’immagine.
Lo script risolve questo problema non alterando i dati dell’astrofotografia, ma adattando dinamicamente quella del logo per corrispondere al range dinamico dell’immagine di destinazione. Solo a questo punto viene calcolata correttamente l’opacità (se scelta dall’utente) per una fusione armonica.
Lo script consente di applicare una firma (in formato PNG con trasparenza) su qualsiasi immagine elaborata, con una serie di opzioni personalizzabili:
- Posizionamento del logo in uno dei nove punti classici dell’immagine: sinistra, centro o destra per ognuna delle tre aree principali (alto, centro, basso).
- Regolazione della dimensione del logo, espressa in percentuale rispetto alla risoluzione dell’immagine.
- Controllo del margine (distanza dal bordo), anch’esso scalabile in percentuale.
- Regolazione dell’opacità, per ottenere un effetto più o meno discreto, sempre in proporzione alla risoluzione.
Tutte le impostazioni sono pensate per adattarsi automaticamente a qualsiasi dimensione dell’immagine, garantendo coerenza visiva anche quando si applica la firma a serie di immagini con risoluzioni diverse.
Come funzione extra particolarmente utile, per massimizzare l’efficienza, lo script permette di salvare e richiamare al volo dei profili di firma preconfigurati.
La grande utilità di questo strumento risiede nel fornire una soluzione integrata, gratuita e totale, che evita all’utente di doversi appoggiare a software di fotoritocco a pagamento, o comunque complessi, per un’operazione così “comune”.
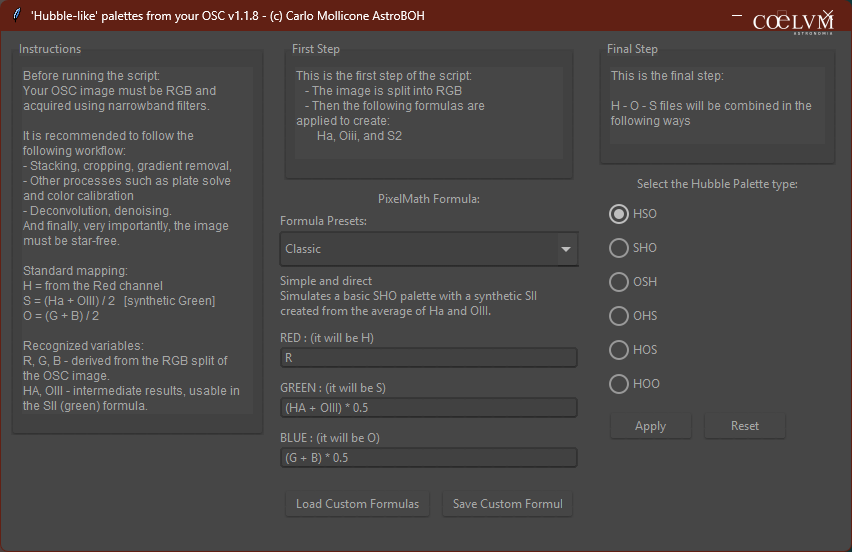
‘Hubble like’ Palette from Dual-Band OSC
Per capire come funziona lo script ‘Hubble like’ Palette from Dual-Band OSC, dobbiamo prima spiegare cosa sono i filtri a doppia banda stretta e perché vengono usati in astrofotografia.
Quando si fotografa il cielo profondo — in particolare le nebulose — non si ottengono colori “naturali” come in una normale foto.
Questo perché le nebulose emettono luci debolissime e concentrate in bande molto strette dello spettro visibile, spesso invisibili all’occhio umano. Le più comuni sono:
- Hα (idrogeno alfa): una luce rossa prodotta dall’idrogeno.
- OIII (ossigeno doppio ionizzato): una luce verde-azzurra prodotta dall’ossigeno.
Per catturare solo queste luci e bloccare tutte le altre (compresa quella dei lampioni o della Luna, il nostro più acerrimo nemico l’inquinamento luminoso che sia di natura artificiale o naturale), si usano filtri a doppia banda stretta, che lasciano passare solo due specifiche lunghezze d’onda.
Nel nostro caso, i filtri sono progettati per far passare solo Hα e OIII (Fig. 6).
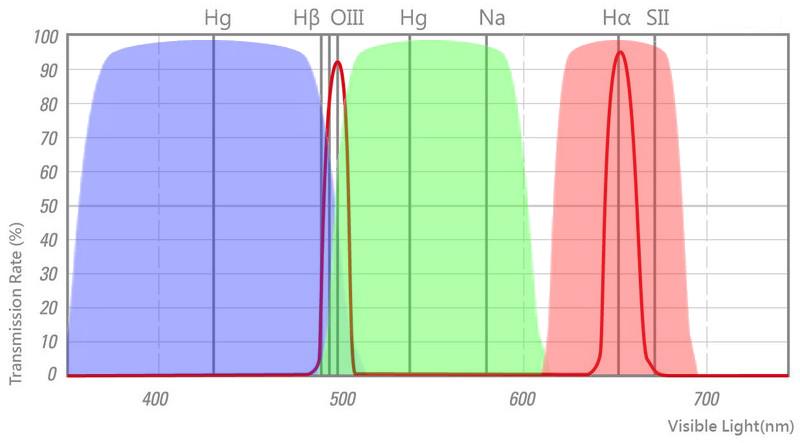
Questi filtri sono particolarmente efficaci se utilizzati con una camera a colori (OSC – One Shot Color), cioè una fotocamera che acquisisce tutti i colori in un singolo scatto.
Quando si scatta con un filtro a doppia banda e una camera OSC, i segnali di Hα e OIII vengono registrati nei canali colore dell’immagine, anche se in modo parzialmente sovrapposto e “mescolato”.
Ed è proprio su questa caratteristica che agisce lo script Hubble like Palette:
analizza il contenuto cromatico dell’immagine e separa i due segnali principali (Hα e OIII), per poi ricombinarli in una palette di colori suggestiva, ispirata a quella resa celebre dal telescopio spaziale Hubble.
Nota: tutto questo funziona solo se l’immagine è stata scattata con un filtro a doppia banda e con una camera a colori. Solo in questo caso lo script può “capire” quali zone dell’immagine corrispondono all’idrogeno e quali all’ossigeno, e assegnare loro i colori corretti.
Ma cosa significa “palette di colori”?
In astrofotografia, soprattutto quando si usano filtri a banda stretta, si applicano i cosiddetti “falsi colori”.
Poiché i segnali catturati non hanno un colore visibile “naturale”, si sceglie come rappresentarli visivamente, assegnando colori specifici a ciascun tipo di emissione. Questo processo si chiama creare una palette.
Ad esempio, una palette chiamata HOO indica che:
- Hα viene mappato nel canale Rosso (R),
- OIII viene duplicato nei canali Verde (G) e Blu (B)
Così, nelle nebulose le zone ricche di idrogeno appaiono rosse, e quelle con molto ossigeno tendono all’azzurro (o meglio ancora ciano un colore tra il blu e il verde, spesso descritto come un blu-verde chiaro o medio).
Un’altra palette molto famosa è la SHO, anche detta “Hubble Palette” (perché è stata usata “creata” per le foto realizzate con il telescopio spaziale Hubble):
- S (zolfo) diventa il Rosso (R),
- H (idrogeno) il Verde (G),
- O (ossigeno) il Blu (B).
Il risultato sono immagini spettacolari, con nebulose dai colori dorati, verdi, turchesi o blu elettrico.
Non si tratta quindi di “truccare” l’immagine, ma di rappresentare informazioni reali (le diverse componenti chimiche) in modo da farle risaltare visivamente.
Ora, Entrare nei dettagli del processo di creazione di queste palette oltre ad essere complicato esula dallo scopo di questo articolo. Tuttavia il programma ‘Hubble like’ Palette from Dual-Band OSC è pensato per venire incontro ad utenti non molto esperti, offrendo una soluzione semplice e automatica per trasformare i dati grezzi raccolti con filtri a doppia banda in immagini dai colori suggestivi, ispirati alla celebre palette del telescopio Hubble, senza richiedere conoscenze tecniche avanzate.
Attraverso una serie di formule (anche personalizzabili) applicate con il PixelMath6 di Siril, lo script separa i canali dell’immagine RGB per ottenere due componenti principali, Ha e OIII, per poi generare un terzo canale “sintetico” lo Zolfo SII (zolfo ionizzato una volta). Questi tre possono poi essere ricombinati in diverse configurazioni cromatiche (SHO, HSO, ecc.), dando vita a rappresentazioni artistiche ma coerenti delle nebulose.
Per garantire la massima flessibilità creativa, offre diversi preset di formule e la possibilità di salvare le proprie.
Tra i preset inclusi troviamo:
- Classica – semplice e diretta: simula una palette SHO base con un falso SII creato dalla media di Ha e OIII.
- Improved – con pulizia del canale OIII: l’OIII è filtrato dalla contaminazione Ha. Il canale SII è sintetizzato come una versione attenuata dell’Ha.
- Advanced – con compressione dinamica e mix pesato: l’OIII è “denoised”, e l’SII è un mix pseudo-spettrale calibrato per migliorare il contrasto tra zone Ha/OIII.
- NonLinear S2 – curva SII (con pow) – per contrasto non lineare: l’SII è simulato con un’espressione non lineare che enfatizza le zone più luminose di Ha.
Va detto che questo non è il procedimento “corretto” in senso stretto (per la creazione delle palette), ma – come già accennato – si tratta di una scorciatoia pensata per utenti poco esperti, che vogliono sperimentare senza doversi addentrare nei dettagli tecnici dell’elaborazione a canali separati.
In ulteriore aggiunta, non tutte le nebulose si prestano a combinazioni cromatiche così spinte o artificiali, ma proprio grazie a un sistema così automatizzato diventa semplice – e anche divertente – provare, confrontare e scoprire nuovi modi di valorizzare i propri dati.
Nota: Cos’è PixelMath in astrofotografia?
Immaginiamo di avere un’immagine astronomica sullo schermo: ogni punto (o “pixel”) ha un valore di luminosità, magari molto basso perché stiamo lavorando con dati grezzi provenienti da una nebulosa lontanissima, ora il nostro intento è chiaro: “vogliamo fare dei calcoli su questi pixel”, per modificarli o combinarli seguendo un approccio rigoroso e scientifico.
Perfetto… PixelMath serve proprio a questo. Ci permette di scrivere delle formule, semplici o complesse, che il software applica a ogni singolo pixel dell’immagine. È un po’ come dire: prendi il valore di questo punto, moltiplicalo, somma un altro canale, applica una curva…, e così via.
Può essere usato per:
Combinare immagini (ad esempio, quelle ottenute con filtri diversi come H-alfa, OIII e SII),
Creare nuovi canali (come uno sintetico SII se non l’hai davvero acquisito),
Bilanciare i colori,
Applicare trasformazioni personalizzate su contrasto, luminosità, o maschere.
In pratica, è uno strumento potentissimo perché ci dà il controllo totale su come vengono trattati i dati dell’immagine. È come avere una calcolatrice dentro il software, ma che lavora su milioni di punti (i “pixel”) contemporaneamente.
Nota: Lo script va utilizzato su immagini non ancora stretchate7 (quindi in fase lineare) a cui sono state tolte le stelle.
Lo stretching e la fase lineare delle immagini astronomiche.
Quando si scatta una foto astronomica, con strumenti come telescopi e camere dedicate, l’immagine che si ottiene inizialmente sembra quasi completamente nera.
Questo succede perché la camera astronomica è uno strumento scientifico e registra la luce in modo lineare. Vuol dire che se un oggetto è due volte più luminoso di un altro, il suo valore sul sensore sarà esattamente il doppio. Il problema è che gli oggetti del cielo profondo sono incredibilmente deboli. La differenza di luminosità tra il fondo cielo, la parte più debole della nebulosa e la parte un po’ meno debole è minuscola. Tutti questi dettagli sono ammassati in una zona scurissima dell’immagine, quasi vicino al nero assoluto. Le stelle, invece, sono migliaia di volte più luminose e occupano l’estremo opposto della scala.
I nostri occhi (e i nostri schermi) non funzionano così. Non riescono a percepire queste differenze minime nel buio.
Ecco che entra in gioco lo stretching (in italiano potremmo dire “stirare” o “allungare”).
Pensiamo a tutti i dati di luminosità di un’immagine astronomica come se fossero scritti su un elastico. A un’estremità ci sono i valori bassissimi della nebulosa: tutti ammassati, appiccicati, praticamente illeggibili. All’altra estremità, molto più lontano, ci sono i valori altissimi delle stelle.
Fare lo stretching significa afferrare proprio la parte dell’elastico dove i dati sono compressi e stirarla con decisione.
In pratica, stiamo dicendo al software: “Prendi tutte quelle piccole e quasi invisibili differenze tra i toni di grigio scuro… e amplificale!”. Così, un grigio che prima era quasi identico a un altro diventa visibilmente più chiaro. È proprio così che, da un fondo apparentemente nero, iniziano ad apparire i deboli filamenti di una nebulosa.
Lo stretching, però, è un’operazione delicata: bisogna “stirare” le zone scure e intermedie senza esagerare con le parti più luminose. Altrimenti le stelle diventano delle palle bianche senza struttura: un effetto che in gergo si chiama bruciare le alte luci.
In sintesi: l’immagine lineare è corretta dal punto di vista scientifico, ma troppo compressa per i nostri occhi. Con lo stretching la trasformiamo in qualcosa di visivamente leggibile e appagante, rivelando tutto ciò che era nascosto nel buio.
Esempio di utilizzo sulla nebulosa “IC 1396 – Proboscide d’elefante”
La Fig. 7 mostra l’immagine di partenza della IC 1396 – Proboscide d’elefante a cui sono state tolte le stelle.
L’immagine presenta una colorazione naturale ma piuttosto piatta: le informazioni relative alla nebulosa sono già presenti, ma non ancora pienamente valorizzate. I dettagli strutturali sono visibili, ma poco contrastati, con dominante cromatica tipica dell’emissione H-alfa in rosso.

La Fig. 8 mostra il risultato della seguente combinazione:
- Formula presets: NonLinear S2
- Hubble Palette type: SHO

La Fig. 9 mostra il risultato ottenuto dopo una fase di stretching dei canali ed alcune semplici operazioni cosmetiche.
In questo caso, non disponendo di un canale SII reale, è stato generato un falso SII tramite una trasformazione non lineare del segnale Ha.

Nello specifico, il canale SII è stato simulato con l’espressione NonLinear S2 – Curva SII (con pow) — una funzione di potenza che enfatizza le zone più luminose dell’idrogeno alfa, creando un effetto di contrasto selettivo nelle aree più energetiche.
Il risultato finale è un’immagine dai forti contrasti, in cui le strutture della nebulosa risultano molto più leggibili. Le tonalità oro e blu — pur non corrispondendo a emissioni reali — aiutano a distinguere le diverse componenti fisiche, come zone dominate da H-alfa, da OIII o regioni polverose.
Flat on Flat Analyzer
Quando fotografiamo il cielo con un telescopio e una camera astronomica, l’immagine che otteniamo non è mai “pulita”. Anche se sembra bella, in realtà è piena di piccoli difetti che l’occhio non nota subito, ma che diventano evidenti quando iniziamo a elaborarla.
Uno di questi problemi è la luce non uniforme sull’intero sensore. Può dipendere da tante cose: polvere sulle lenti o sul sensore, vignettatura (cioè i bordi dell’immagine che risultano più scuri), piccoli difetti nell’ottica o nel treno fotografico. Ed è qui che entrano in gioco i flat.
I flat field sono foto speciali, scattate a una superficie bianca e uniforme (come il cielo all’alba o uno schermo piatto illuminato), con la stessa configurazione ottica usata per le foto al cielo. Servono per “fotografare/catturare” proprio quei difetti: le macchie di polvere, le zone più scure ai bordi, le piccole irregolarità, la vignettatura.
Una volta che abbiamo questo flat, il software lo usa per correggere ogni singolo pixel dell’immagine vera. È come se dicessimo al programma: “guarda che in questo punto c’è una macchia, non è colpa del cielo”. Così possiamo ripulire l’immagine e ottenere un risultato più fedele e uniforme.
Senza i flat, anche la foto più bella può avere zone più scure, aloni strani o cerchi causati da polvere che rovinano tutto. Con i flat invece, tutto si livella, e quello che resta è davvero luce proveniente dallo spazio.
Purtroppo, i flat sono un po’ la bestia nera degli astrofotografi. Che si sia alle prime armi o con anni di esperienza, il dubbio di non averli fatti bene è sempre dietro l’angolo.
Ma con un po’ di pratica e qualche test o strumento, diventa tutto più naturale e una volta che si impara a farli bene, non se ne può più fare a meno.
Qui entra in gioco il mio programma Flat on Flat Analyzer, uno strumento puramente diagnostico, pensato per valutare la qualità e la coerenza dei flat field: un passaggio cruciale, eppure spesso trascurato (come descritto prima, data la difficoltà nell’acquisirli), nel flusso di calibrazione delle immagini.
Questo test è essenziale per verificare la stabilità del treno ottico e l’uniformità della sorgente di illuminazione (flat-box, lavagne luminose), sia tra sessioni diverse che all’interno della stessa notte.
Lo script applica la tecnica “flat-on-flat”: un metodo semplice ma poco conosciuto, particolarmente efficace nel far emergere problemi difficili da rilevare visivamente.
L’analisi si basa sulla divisione tra due master flat (uno di riferimento e uno da verificare), secondo la formula:
(Flat_Verificato / Flat_Riferimento) × med(Flat_Riferimento)
Se il sistema è stabile e i flat sono coerenti, il risultato sarà un’immagine perfettamente uniforme. Al contrario, gradienti e artefatti metteranno subito in luce anomalie legate a flessioni meccaniche, variazioni nella luce di calibrazione o errori di acquisizione.
Oltre alla valutazione visiva, lo script fornisce anche un’analisi numerica: la deviazione standard dell’immagine risultante funge da indice oggettivo di coerenza. Valori inferiori all’1,5% indicano generalmente un’elevata affidabilità del setup.
Come valore aggiunto, il risultato viene rappresentato in una mappa 3D interattiva, in grado di rendere evidenti anche le più sottili disuniformità.
Esempio di confronto tra due master flat ottenuti con due pannelli luminosi diversi e treno ottico uguale.
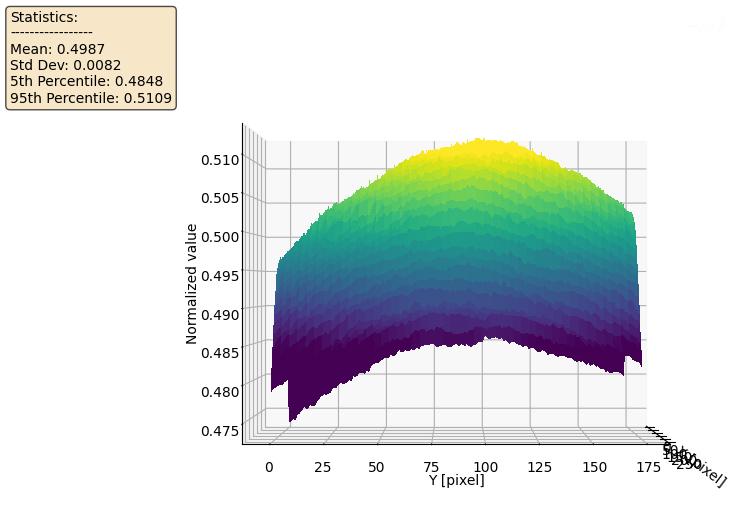
- Master Flat di Riferimento Figura 11 perfettamente concentrico, questo sarà il nostro riferimento.
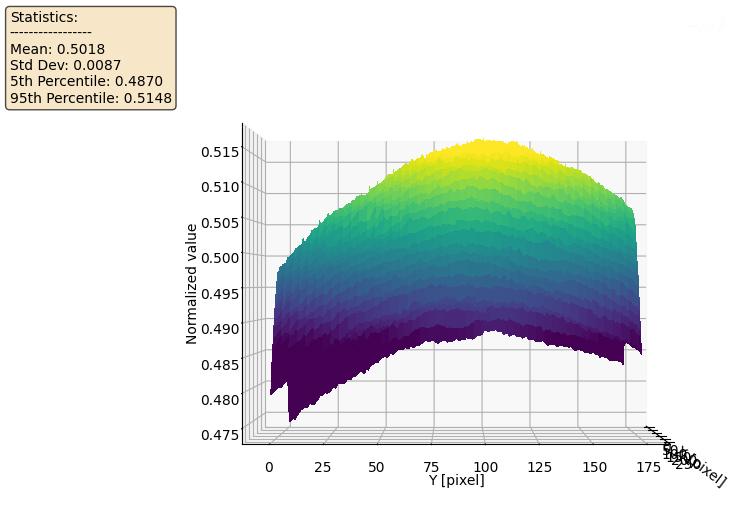
- Master Flat da verificare Figura 12 ottenuto con un pannello più grande e molto decentrato.
Risultato del test di omogeneità (FigG. 13, 14 e 15)
L’esito del test di omogeneità è eccellente.
Vediamo perché:
Flat Iniziali: Sia il “Flat di Riferimento” (Fig. 11) che il “Flat da verificare” (Fig. 12) mostrano una deviazione standard (Std Dev) di circa 0.008. Questo valore rappresenta la disomogeneità totale, che include sia la vignettatura e la polvere (il segnale che vogliamo correggere) sia il rumore intrinseco del sensore. La forma a “cupola” del grafico 3D mostra chiaramente questa vignettatura.
Risultato Finale: L’immagine finale del test “Flat-on-Flat” (Fig. 13) ha una deviazione standard di appena 0.0007.
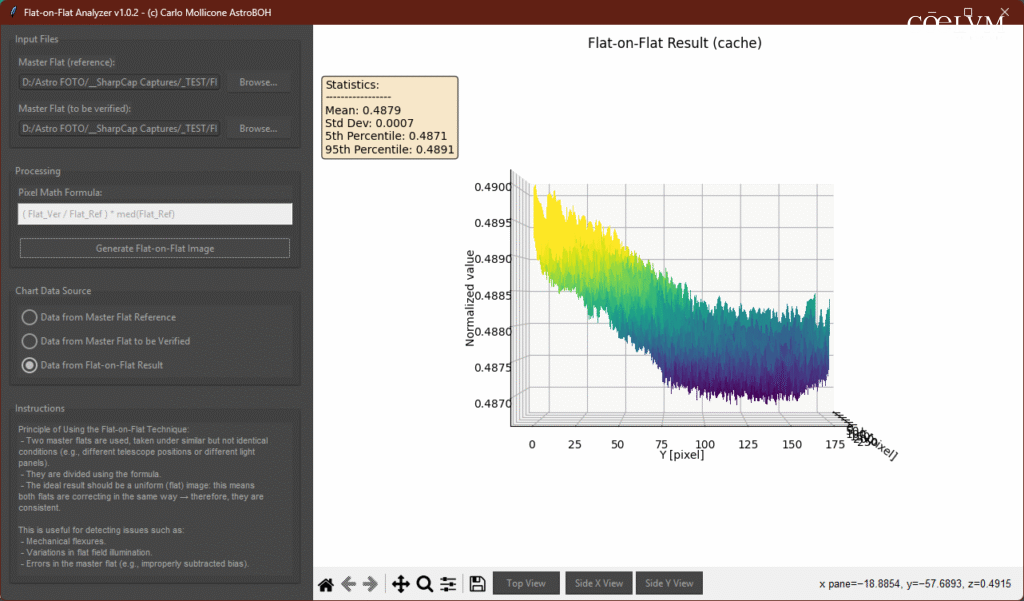
Questo crollo drastico della deviazione standard (da 0.008 a 0.0007, più di 10 volte inferiore!) è la prova che i due flat sono estremamente coerenti e il sistema è molto stabile.
Tuttavia, un’analisi approfondita dei grafici ci consente di rivelare una storia più sottile e interessante, Fig. 14.
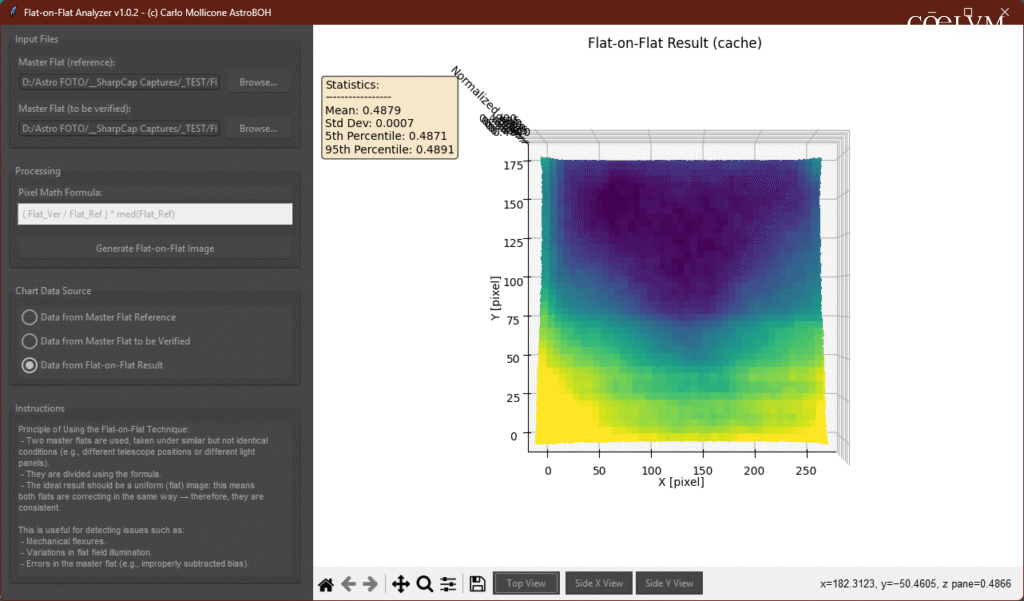
La Mappa 2D (Figura 14) mostra la Causa
La mappa 2D e la superficie 3D ci mostrano la natura di questa differenza sistematica: si tratta di un gradiente molto debole su larga scala. Si può vedere, c’è una transizione fluida da valori leggermente più bassi (la zona viola) a valori leggermente più alti (la zona gialla), mentre non ci sono difetti evidenti come polvere o artefatti del sensore.
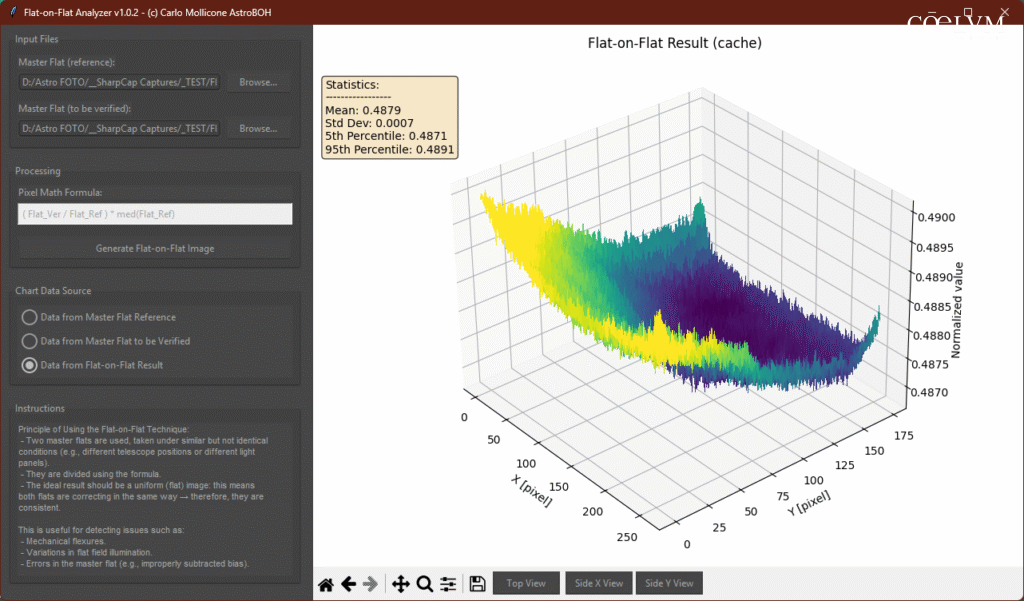
Sintesi della Diagnosi
Mettendo insieme le informazioni, possiamo concludere che: I due master flat sono quasi identici, ma presentano una lievissima differenza nella loro illuminazione su larga scala. Quando vengono divisi, questa piccola differenza di gradiente produce un’immagine risultante che non è perfettamente uniforme, ma che ha due “zone” principali di luminosità.
Un gradiente così debole è spesso il risultato di Una minima variazione nell’illuminazione del flat panel. Considerando che il Master
Flat da verificare (Fig. 12) è stato acquisito con un pannello più grande e molto decentrato, la spiegazione torna e conferma l’utilità dello script.
Nota: I flat sono comunque di altissima qualità e la differenza rilevata è puramente accademica. Un gradiente così debole, quantificato da una deviazione standard di appena 0.0007, è assolutamente trascurabile e non avrà alcun impatto visibile sulle nostre immagini calibrate.
Valori di Riferimento per gli Utenti
Possiamo usare la deviazione standard (Std Dev)8 del risultato finale come un indice numerico per giudicare la qualità del test. Ecco una scala di riferimento semplice e pratica da usare:
- Std Dev < 0.0015 (o 0.15%): Risultato Eccellente. I flat sono estremamente coerenti e il tuo sistema ottico è molto stabile. Qualsiasi disomogeneità residua è del tutto trascurabile e non influenzerà l’immagine finale.
- Std Dev tra 0.0015 e 0.0030 (tra 0.15% e 0.3%): Risultato Buono/Accettabile. C’è una lievissima differenza tra i due flat, che potrebbe essere dovuta a una minima flessione o a una leggera variazione nell’illuminazione. È un risultato comunque molto buono e i flat sono perfettamente utilizzabili senza problemi.
- Std Dev > 0.0030 (o 0.3%): Risultato da Investigare. Una deviazione standard superiore a questa soglia indica una differenza significativa tra i due flat. Non significa che siano da buttare, ma è un campanello d’allarme. L’utente dovrebbe verificare se ci sono state flessioni nel treno ottico, se il flat-box si è spostato, se la luce ambientale è cambiata durante l’acquisizione o se ci sono problemi nella calibrazione dei flat stessi (es. dark o bias non corretti).
Satellite Trail Remover
Ritengo questo strumento uno dei contributi più rilevanti della suite, sviluppato per affrontare uno dei problemi più frustranti dell’astrofotografia moderna: le tracce lasciate dai satelliti artificiali. Il fenomeno, un tempo sporadico, è oggi in forte aumento a causa del lancio di migliaia di satelliti appartenenti a mega-costellazioni come Starlink, OneWeb, Kuiper e altri progetti emergenti. Le pose lunghe — fondamentali per ottenere immagini profonde — sono sempre più a rischio di venire rovinate da queste scie luminose.
Nota: Secondo lo IAU Centre for the Protection of the Dark and Quiet Sky, il numero di satelliti artificiali in orbita è passato da circa 2.000 nel 2019 a oltre 9.000 nel 2025, con proiezioni che parlano di oltre 100.000 entro il 2030. Le osservazioni notturne sono già influenzate, con alcune esposizioni astro fotografiche che mostrano più di una decina di tracce satellitari visibili. Fonte: https://cps.iau.org
Recuperare una singola posa, magari da 5 o 10 minuti, rovinata dal passaggio di un satellite, è di un valore inestimabile.
Questo script fornisce un’interfaccia avanzata per affrontare il problema.
Ci sono due approcci:
Approccio Manuale
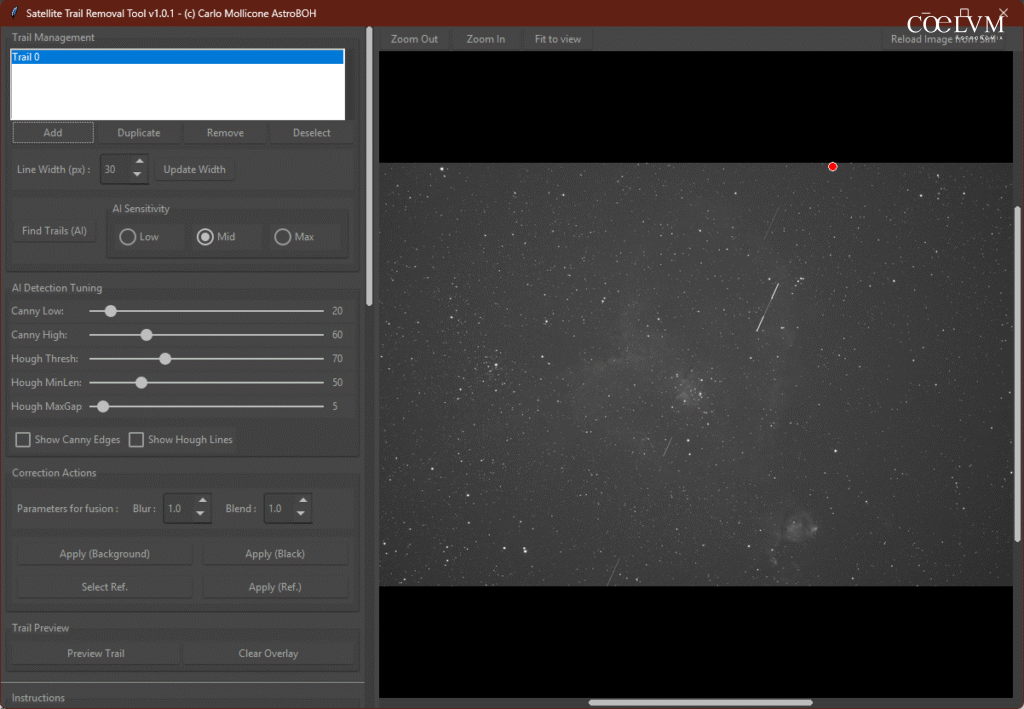
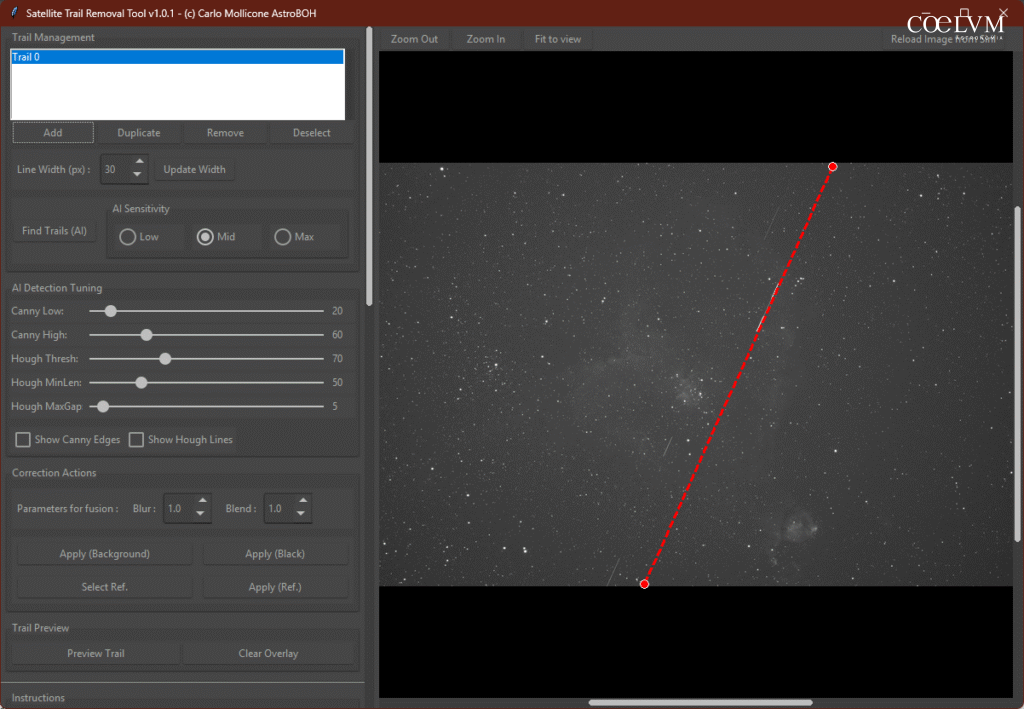
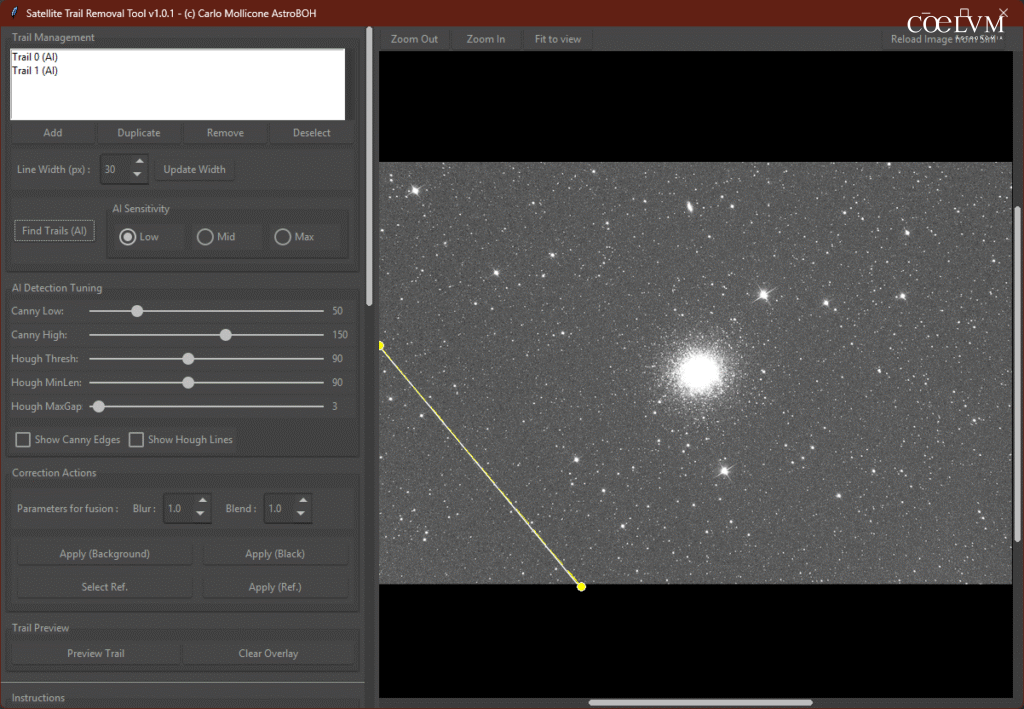
L’utente può tracciare manualmente una linea retta cliccando sul pulsante “Add”, selezionando un punto di inizio Fig. 17 – Primo Click e uno di fine Fig. 18 – Secondo Click.
Questa linea può poi essere convertita in una “spline” — una curva regolare, liscia e continua, definita da una serie di punti di controllo — semplicemente aggiungendo nuovi punti sull’anteprima dell’immagine.
Rilevamento Automatico
Utilizzare una funzione di rilevamento automatico basata su algoritmi di visione artificiale (l’algoritmo di Canny e la Hough Transform) per tentare di identificare le tracce.
Una volta definita la maschera (la nostra linea o spline sopra le tracce dei satelliti), possiamo decidere come “riempirla”:
- Con una stima avanzata dello sfondo (utilizzando l’algoritmo DAOPHOT MMM: media, mediana, moda);
- Con nero puro (valore 0), (questo è un piccolo trucco, perché i pixel neri sono automaticamente esclusi dal calcolo dello stacking da tutti i software di stacking);
- Con un’immagine di riferimento (in genere il fotogramma precedente o successivo) da cui vengono copiati i pixel per riempire l’area della traccia mascherata.
Questo è il funzionamento in linea di principio, ma ora entriamo nel dettaglio descrivendo gli algoritmi ed i passaggi chiave necessari per il riconoscimento automatico delle tracce satellitari.
Per chi non ha familiarità con la visione artificiale, può sembrare sorprendente che un software riesca a “vedere” una traccia sottile in mezzo al rumore di fondo di un’immagine astronomica. In realtà, tutto si basa su alcuni algoritmi “intelligenti”, il primo dei quali è il Canny Edge Detector.
Canny Edge Detector: trovare i contorni.
Nell’elaborazione di immagini, l’algoritmo di Canny è un operatore per il riconoscimento dei contorni (edge detection) ideato nel 1986 da John F. Canny.
Immaginiamo di avere un’immagine in bianco e nero leggermente sfocata (per ridurre il rumore e semplificare i contorni), con tanti dettagli deboli. Il Canny è un algoritmo che analizza l’immagine pixel per pixel per cercare i contorni netti, ovvero quei punti in cui c’è un cambiamento improvviso di luminosità. Detto in parole povere: trova i bordi.

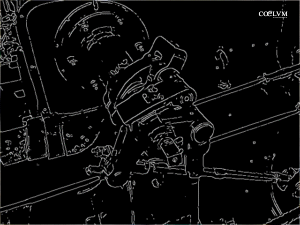
Nel caso di una scia satellitare, che è una linea chiara o scura che attraversa il fotogramma, il Canny riesce a isolare proprio quel bordo sottile rispetto al resto del cielo, creando un’immagine “filtrata” fatta solo di bordi. Non decide ancora se si tratti di una scia, ma mette in evidenza tutte le forme allungate e marcate.
La trasformata di Hough: riconoscere le linee.
A questo punto entra in gioco “la trasformata di Hough”. Questo nome complicato nasconde un’idea semplice ma geniale: tra tutte le linee possibili che si possono formare dai bordi trovati prima da Canny, l’algoritmo cerca quelle dritte, continue e ben definite.
Matematicamente è semplicemente la trasformata di Radon nel piano, nota almeno dal 1917, ma la trasformata di Hough si riferisce al suo utilizzo nell’analisi delle immagini.
La trasformata di Hough, così come è universalmente utilizzata oggi, è stata inventata da Richard Duda e Peter Hart nel 1972, che la chiamarono “trasformata di Hough generalizzata” dopo il brevetto correlato del 1962 di Paul Hough. La trasformata è stata resa popolare nella comunità della visione artificiale da Dana H. Ballard attraverso un articolo di giornale del 1981 intitolato “Generalizing the Hough transform to detect arbitrary shapes”.
In pratica e molto banalmente, è come se prendesse l’immagine piena di contorni e dicesse: “fammi vedere se c’è una linea netta che attraversa da una parte all’altra”.
Nel nostro caso, se c’è una scia satellitare, questa ha proprio quella forma: una linea dritta, più o meno lunga, che attraversa il campo. E la trasformata di Hough è bravissima a trovarla, anche in mezzo al rumore.
Vantaggi della trasformata di Hough
- Robustezza: è in grado di rilevare forme anche se parzialmente oscurate, degradate o immerse nel rumore.
- Semplicità: è concettualmente semplice, il che la rende relativamente facile da comprendere e implementare.
- Versatilità: può essere adattata per rilevare diverse forme geometriche, non solo linee ma anche cerchi ed ellissi.
- Rilevamento globale: permette di identificare strutture nell’intera immagine, non solo in aree localizzate.
Svantaggi della trasformata di Hough
- Elaborazione intensiva: può essere lenta e richiedere risorse computazionali elevate, soprattutto con immagini grandi o forme complesse.
- Sensibilità ai parametri: richiede un’attenta regolazione di parametri come la risoluzione dello spazio dei parametri, per bilanciare precisione e prestazioni.
- Sensibilità al rumore: in presenza di molto rumore può generare falsi positivi o rilevamenti errati.
Quantizzazione: la natura discreta dello spazio dei parametri può introdurre una perdita di precisione nel rilevamento delle forme.
Esempio di applicazione di Canny ed Hough nella “visione artificiale” per la guida autonoma.
Passo 1, l’algoritmo di Canny ha evidenziato i contorni (fig. 21).

Passo 2, l’algoritmo di Hough ha “creato” delle linee (vettori con coordinate x, y) che ora possono essere “lette” ed analizzate dal software (fig. 22).

Questo è il cuore del riconoscimento automatico: prima si cercano i contorni con Canny, poi, tra quei contorni, si individuano le linee vere e proprie con Hough. Quando entrambi gli algoritmi trovano qualcosa che ha senso, lo script è in grado di proporre all’utente una traccia, che può essere corretta, confermata o scartata.
Ora sorge un problema, le immagini astronomiche, per loro natura, sono molto deboli, rumorose e, in alcuni casi, dense di stelle, quindi piene di punti che possono allinearsi casualmente uno dietro l’altro. Questo fa sì che i falsi positivi nel riconoscimento delle scie satellitari siano piuttosto frequenti.
Ed è proprio qui che entra in gioco l’algoritmo di fusione delle tracce da me scritto.
La Concezione dell’Algoritmo
L’idea fondamentale dietro questo algoritmo è di emulare il processo cognitivo umano: di fronte a una serie di piccoli trattini allineati, il nostro cervello non li percepisce come entità separate, ma li raggruppa istintivamente in una o più linee continue. L’algoritmo adotta un approccio “bottom-up”: parte dai più piccoli elementi disponibili (i segmenti di Hough) e li assembla in strutture più grandi e significative (le tracce complete).
Il processo si articola in quattro fasi logiche fondamentali:
- 1. Filtro del Rumore: Eliminazione dei segmenti irrilevanti.
- 2. Raggruppamento per Prossimità: Identificazione dei segmenti che appartengono alla stessa traccia.
- 3. Unione e Analisi: Fusione dei segmenti raggruppati in un’unica linea e calcolo delle sue proprietà (come la larghezza).
- 4. Estrapolazione: Estensione della linea risultante per coprire l’intera immagine.
Messier 13 – Un esempio concreto
A seguire alcune indicazioni operative sull’uso dell’auto-detection, con un caso particolarmente ostico (fig. 23) ed il risultato di un “Find Trail with AI” (fig. 24).

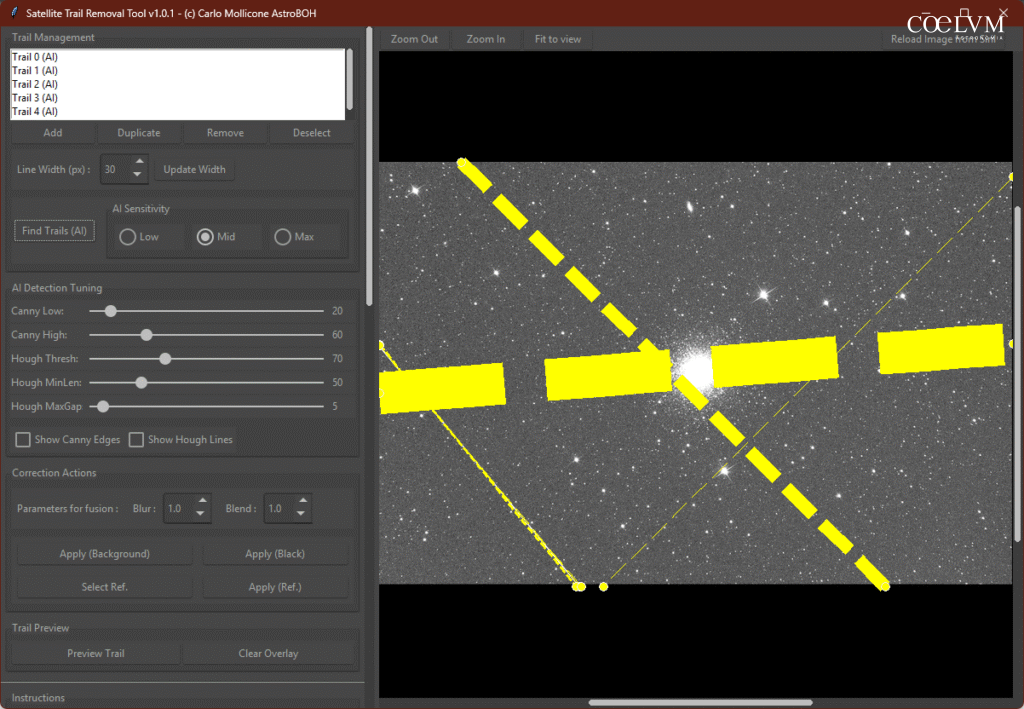
Questo “fallimento” nel riconoscimento delle tracce come già detto è frutto della natura particolare dell’immagine astronomiche. La grande presenza stellare di M13 ha concentrato molti punti sulle stelle che sono diventate linee per Hough.
Grazie ai flag che inizialmente avevo usato solo per test, alla fine mi sono deciso a lasciarli attivi nel progetto finale in quanto li ho trovati incredibilmente utili per trovare e calibrare i corretti valori della “visione artificiale” e quindi avere un riconoscimento automatico della traccia abbastanza preciso (non infallibile).
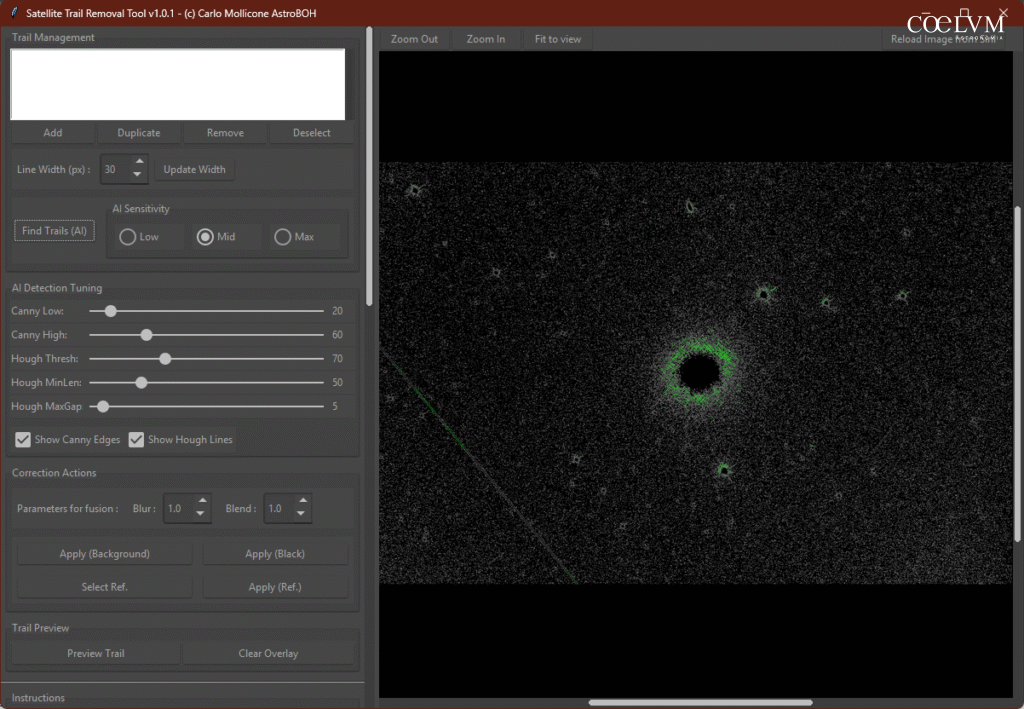
È chiara la linea verde sulla traccia, ma ci sono anche molte linee verdi intorno al nucleo di M13.
Come risolvere?
Banalmente, con l’inserimento di una traccia manuale, oppure possiamo divertirci con la ricerca dei giusti parametri per l’auto detection.
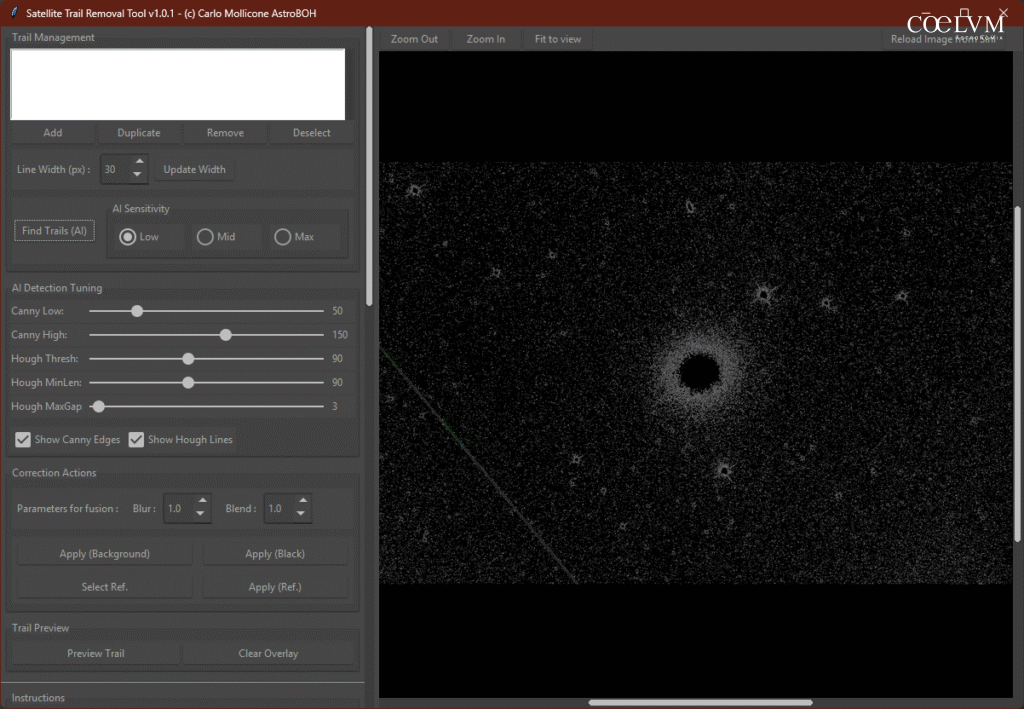
Il primo approccio è selezionare un preset di AI Sensitivity tra “Low, Mid, Max”.
In questo caso abbiamo scelto “Low” bassa sensibilità e poi abbiamo anche diminuito notevolmente il parametro Hough MaxGap a “3”, cliccando su “Find Trails AI” con entrambi i flag di test attivi abbiamo ottenuto un’immagine molto “pulita” (fig. 27). Per verifica finale, togliamo i flag su “Show Canny Edges” e “Show Hough Lines”, quindi clicchiamo su “Find Trails AI” (fig. 28).
Le due linee sono praticamente sovrapposte, ne possiamo cancellare una ed allargare la rimanente per avere una sicura copertura della traccia (fig. 29).
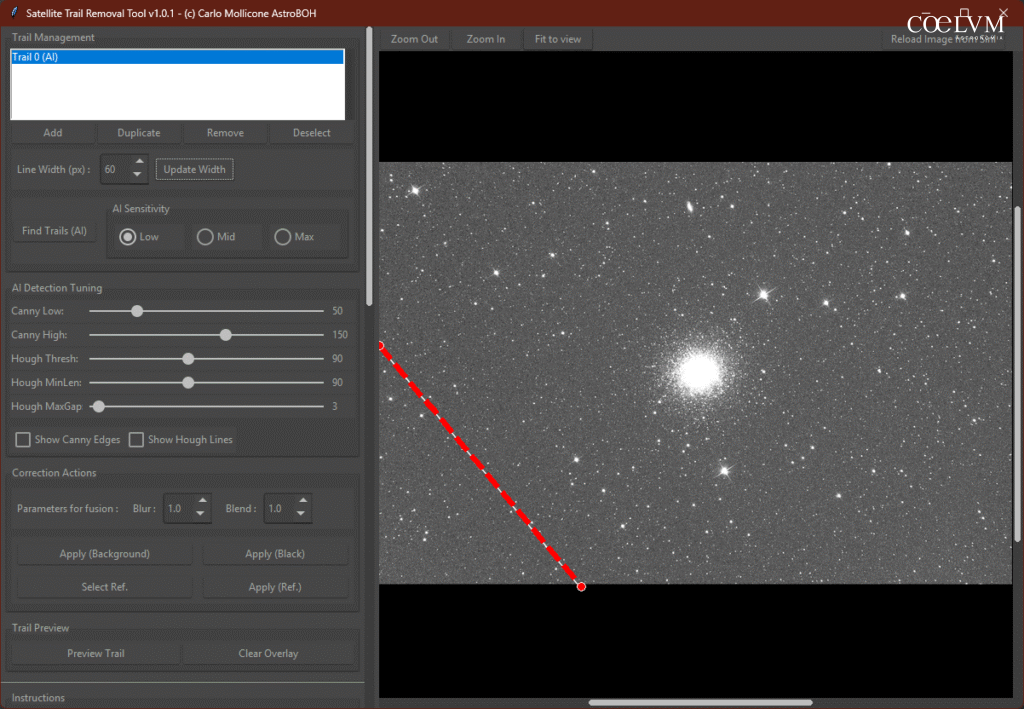
A questo punto, possiamo per verifica finale avere un’anteprima del corretto posizionamento cliccando su “Preview Trail”
Per ultimo, non ci resta che scegliere come nascondere la traccia, con i metodi già elencati.
Questo era un caso limite che ho scelto di affrontare passo passo come guida di utilizzo, in molti altri casi l’auto detection funziona molto bene ed al massimo si deve solo scegliere tra i preset di AI Sensitivity “Low, Mid, Max”.
Satellite Trail Remover si è dimostrato uno strumento efficace e robusto per la rimozione di tracce satellitari, superando le sfide poste sia dal rilevamento di tracce deboli che dalla corretta fusione di segmenti multipli.
L’algoritmo di fusione delle tracce, ha fornito risultati eccellenti su un’ampia gamma di immagini campione.
Possibili sviluppi futuri potrebbero includere:
- L’implementazione di algoritmi di clustering più avanzati (es. HDBSCAN) per una maggiore robustezza.
- L’addestramento di un semplice classificatore per distinguere le tracce satellitari da altri artefatti lineari (es. diffrazione stellare).
Conclusioni e ringraziamenti
Strumenti nati da esigenze reali, come quelli qui presentati, non solo semplificano il flusso di lavoro personale, ma possono essere condivisi per arricchire l’esperienza collettiva. La possibilità di automatizzare, diagnosticare e recuperare dati tramite script personalizzati cambia radicalmente l’approccio all’elaborazione: lo rende più efficiente, creativo e consapevole dal punto di vista scientifico.
Spero che questo contributo possa ispirare altri astrofili a esplorare le potenzialità dello scripting in Python per Siril, partecipando attivamente alla crescita di questo straordinario progetto.
Un ringraziamento speciale va al team di sviluppo di Siril, per l’instancabile lavoro e supporto tecnico, alla comunità dell’Associazione Tuscolana di Astronomia (ATA) per avermi fatto crescere in un ambiente fertile di confronto e crescita continua ed infine ai ragazzi con cui ho fondato il gruppo AstroBOH.
link
Gli script e la documentazione sono disponibili liberamente al seguente indirizzo: https://gitlab.com/free-astro/siril-scripts
L’Associazione Tuscolana di Astronomia (ATA): https://lnx.ataonweb.it/wp/
Il gruppo degli AstroBOH : www.astroboh.it
NOTE
- Lo stacking, quando si fotografa il cielo, soprattutto oggetti debolissimi come nebulose o galassie lontane, una sola foto non basta. Il segnale è troppo debole e il rumore — vale a dire quei disturbi fastidiosi che rendono l’immagine granulosa — è troppo alto.
È qui che entra in gioco lo stacking.
Lo stacking non è altro che un modo matematico per sommare o mediare tante foto dello stesso oggetto, scattate una dopo l’altra, per ottenerne una sola ma molto più pulita.
In sintesi: lo stacking è il trucco principale che gli astrofotografi usano per tirare fuori il segnale nascosto nelle profondità del cielo. Senza, la maggior parte delle foto astronomiche sembrerebbero solo rumore grigio con qualche stellina. - In Python, gli ambienti virtuali sono una funzionalità importante per isolare le dipendenze e le configurazioni dei progetti. Un ambiente virtuale è una cartella che contiene una copia privata di Python e di tutti i pacchetti installati. Ciò significa che ogni progetto può avere la sua versione di Python e di pacchetti specifici, senza influire sugli altri progetti.
- I file FITS (Flexible Image Transport System) sono un formato usato soprattutto in astronomia per archiviare immagini e dati scientifici. A differenza delle immagini comuni (come JPEG o PNG), i file FITS contengono non solo i pixel, ma anche molte informazioni aggiuntive.
In pratica, un file FITS è un “contenitore” con:
• L’immagine (spesso in bianco e nero, a 16 o 32 bit per pixel, anche con virgola mobile).
• Un’intestazione con tutti i dati utili per capire cosa si sta guardando: quale telescopio ha scattato l’immagine, quando, con quale filtro, quanto è durato lo scatto, ecc.
• Eventuali tabelle o grafici aggiuntivi (non solo immagini).
È uno standard molto usato da osservatori professionali e amatoriali perché mantiene alta precisione e consente di fare analisi scientifica sui dati. Chi fa astrofotografia lo usa per elaborare le immagini e lo mantiene fino alla fine del processo di elaborazione per non perdere “informazioni”. - Ad esempio, una maschera come light_*.fit eliminerebbe tutti i file che iniziano con “light_” e terminano con “.fit”, senza distinguere se appartengano davvero alla sequenza corrente o a un’altra. L’asterisco (*) in una maschera di nomi file è un carattere jolly che sta a significare “qualsiasi cosa, anche nulla”.
Nel contesto delle maschere usate nei file system o negli script, serve per selezionare più file che condividono una parte del nome, senza doverli elencare uno per uno.
In dettaglio, la maschera light_*.fit significa:
“Tutti i file che iniziano con light_ e finiscono con .fit, indipendentemente da cosa c’è in mezzo”.
Quindi selezionerebbe:
• light_0001.fit
• light_finale.fit (PERICOLO!!!, potrebbe cancellare il file finale)
• light_test.fit
• light_.fit - PARSING, in pratica, significa leggere il file riga per riga seguendo delle regole precise, per capire cosa contiene e come è strutturato.
8. La deviazione standard (Std Dev), quando parliamo di un’immagine astronomica, misura quanto i pixel differiscono tra loro rispetto alla media.
Se l’immagine è tutta uniforme (ogni pixel ha più o meno lo stesso valore), la deviazione standard è bassa.
Se ci sono zone molto più chiare o scure di altre (vignettatura, polvere, gradienti, stelle), la deviazione standard è alta.
È un po’ come dire: “quanto è irregolare il terreno?”
Terreno piatto → valori simili → Std Dev bassa.
Terreno con colline e valli → valori molto diversi → Std Dev alta.
[/swpm_protected]
L’articolo è pubblicato in COELUM 276 VERSIONE CARTACEA








